Leçon 5.9 : Algorithmes de jointure — Comment la base de données exécute les jointures
Dans les leçons précédentes, nous avons écrit des jointures SQL en nous concentrant sur quelles données elles retournent. Mais comment la base de données exécute-t-elle réellement une jointure sous le capot ? Comprendre les algorithmes physiques utilisés par le moteur est essentiel pour écrire des requêtes performantes sur de grands ensembles de données.
Les trois principaux algorithmes de jointure sont :
- Nested Loop Join (jointure par boucles imbriquées)
- Hash Join (jointure par hachage)
- Merge Join (jointure par fusion, aussi appelée Sort-Merge Join)
Le planificateur de requêtes choisit automatiquement l'algorithme en fonction de la taille des tables, des index disponibles et de la mémoire. Nous ne pouvons pas imposer un algorithme spécifique en SQL standard, mais comprendre les compromis nous permet d'écrire des requêtes et de créer des index qui orientent le planificateur vers le meilleur choix.
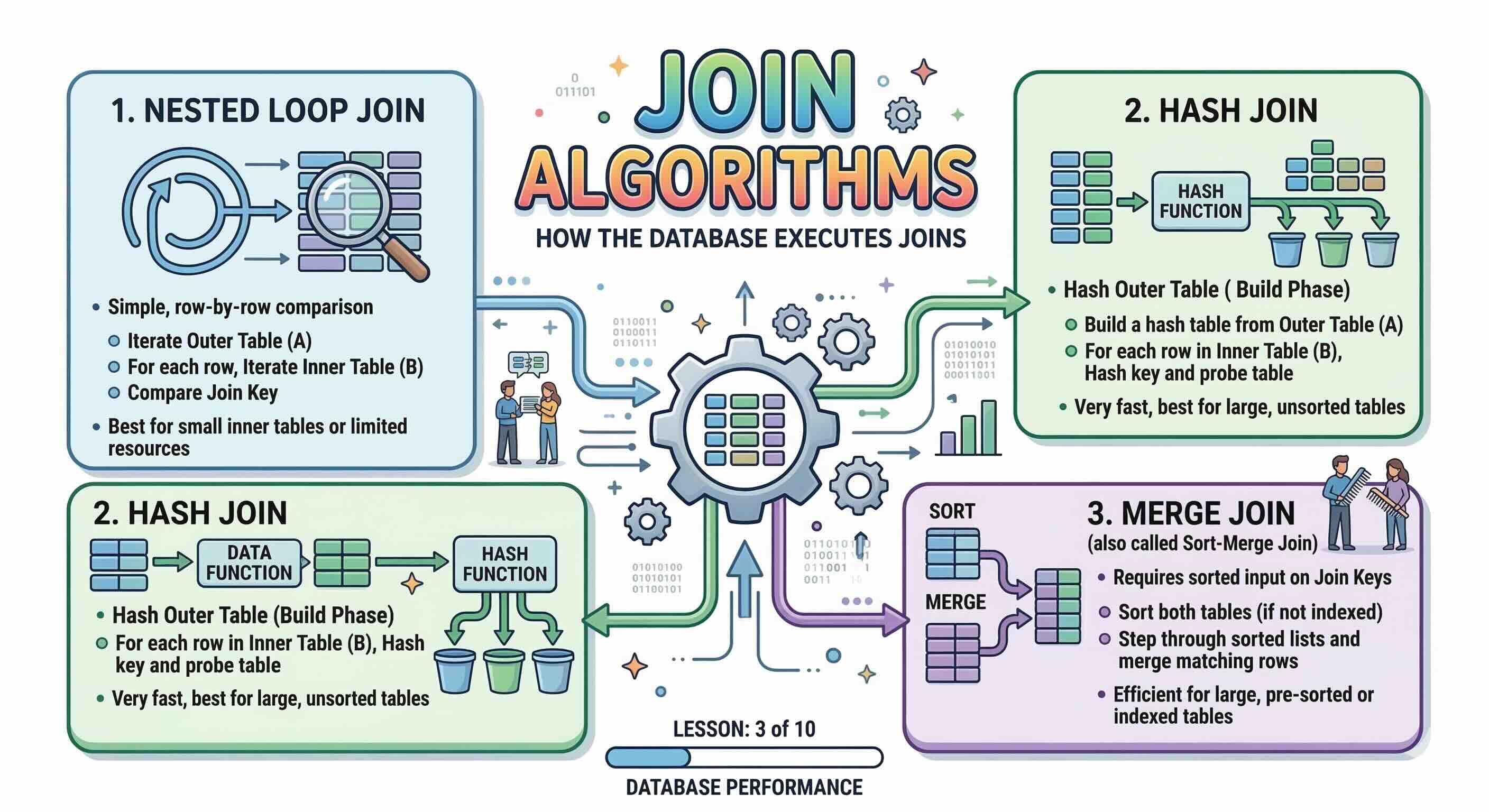
1. Nested Loop Join (jointure par boucles imbriquées)
Fonctionnement
Le Nested Loop Join est l'algorithme le plus simple. La base de données choisit une table comme table externe (conductrice) et l'autre comme table interne. Elle itère ensuite sur chaque ligne de la table externe et, pour chaque ligne, recherche des correspondances dans la table interne — deux boucles for imbriquées en substance.
Pseudo-code conceptuel :
for each row R1 in outer_table:
for each row R2 in inner_table:
if R1.key = R2.key:
output(R1, R2)
Lorsqu'un index existe sur la colonne de jointure de la table interne, le balayage interne devient une recherche d'index rapide au lieu d'un balayage complet de la table. Cette variante est appelée Index Nested Loop Join et est l'un des chemins d'exécution les plus efficaces possibles.
Quand le planificateur l'utilise
- La table externe (conductrice) est petite.
- Un index existe sur la colonne de jointure de la table interne.
- La jointure utilise une condition de non-égalité (
<,>,BETWEEN) — Hash Join et Merge Join nécessitent l'égalité, donc Nested Loop est la seule option dans ce cas.
Avantages et inconvénients
| Nested Loop Join | |
|---|---|
| Avantages | Fonctionne avec n'importe quelle condition de jointure, y compris les conditions de plage |
| Extrêmement rapide lorsque la table externe est petite et la table interne indexée | |
| Faible consommation de mémoire — pas besoin de construire des structures de données auxiliaires | |
Commence à retourner les premiers résultats immédiatement (idéal pour les requêtes avec LIMIT) | |
| Inconvénients | Très lent sur les grandes tables sans index — O(N × M) dans le pire cas |
| Les performances se dégradent rapidement à mesure que les deux tables croissent |
2. Hash Join (jointure par hachage)
Fonctionnement
Un Hash Join fonctionne en deux phases :
- Phase de construction (Build phase) : La base de données lit la table la plus petite et construit une table de hachage en mémoire, dont la clé est la colonne de jointure.
- Phase de sondage (Probe phase) : La base de données balaye la table la plus grande et, pour chaque ligne, consulte la table de hachage pour trouver les correspondances.
Pseudo-code conceptuel :
-- Phase de construction
hash_table = {}
for each row R1 in smaller_table:
hash_table[ hash(R1.key) ].append(R1)
-- Phase de sondage
for each row R2 in larger_table:
for each match in hash_table[ hash(R2.key) ]:
if R2.key = match.key:
output(R2, match)
Cela donne une complexité globale de O(N + M) — linéaire pour les deux tailles de tables — ce qui le rend bien plus évolutif qu'un Nested Loop Join sans index.
Quand le planificateur l'utilise
- Jointure de deux grandes tables sur une condition d'égalité.
- Aucun index utile n'existe sur la ou les colonnes de jointure.
- Assez de mémoire est disponible pour contenir la table de hachage (
work_memdans PostgreSQL).
Avantages et inconvénients
| Hash Join | |
|---|---|
| Avantages | Très efficace pour les jointures de grandes tables — O(N + M) |
| Ne nécessite pas d'index sur les colonnes de jointure | |
| Gère bien les données non triées et non ordonnées | |
| Inconvénients | Nécessite une condition d'égalité — ne peut pas être utilisé pour les jointures par plage |
| Gourmand en mémoire : si la table de hachage ne tient pas en RAM, elle est déversée sur le disque (beaucoup plus lent) | |
| Coût de démarrage élevé — la table de hachage doit être construite avant de retourner les premiers résultats |
Note : Dans PostgreSQL, vous pouvez contrôler le budget mémoire avec le paramètre work_mem. L'augmenter réduit le risque de déversements disque coûteux lors de grands Hash Joins.
3. Merge Join (jointure par fusion)
Fonctionnement
Un Merge Join exige que les deux tables d'entrée soient triées sur la colonne de jointure. Il fusionne ensuite les deux flux triés simultanément — comme l'étape finale de l'algorithme classique Merge Sort — en avançant un pointeur dans chaque flux pour trouver les correspondances.
Pseudo-code conceptuel :
sort outer_table by key -- ignoré si un index ordonné est utilisé
sort inner_table by key -- ignoré si un index ordonné est utilisé
p1 = début de outer_table
p2 = début de inner_table
while pas fin de l'un ou l'autre flux :
if outer[p1].key = inner[p2].key :
retourner les lignes correspondantes et avancer les deux pointeurs
elif outer[p1].key < inner[p2].key :
avancer p1
else :
avancer p2
L'optimisation cruciale : si la table peut être balayée via un index ordonné, l'étape de tri est gratuite et le Merge Join devient l'un des algorithmes les plus efficaces disponibles.
Quand le planificateur l'utilise
- Les deux tables sont grandes et la condition de jointure est l'égalité.
- Les deux tables sont déjà triées, ou les deux peuvent être balayées via un index ordonné.
- La requête nécessite déjà un
ORDER BYouGROUP BYsur la colonne de jointure (le tri aura de toute façon lieu).
Avantages et inconvénients
| Merge Join | |
|---|---|
| Avantages | Très efficace pour les grandes tables lorsque les données sont pré-triées ou qu'un index ordonné existe |
Produit les résultats dans l'ordre trié, ce qui peut éliminer une étape ORDER BY ultérieure | |
| Consommation de mémoire stable et prévisible | |
| Inconvénients | Nécessite uniquement une condition d'égalité |
| Étape de tri explicite coûteuse si aucune table n'est pré-triée et qu'aucun index n'est disponible | |
| Moins flexible que Hash Join pour les données complètement non triées |
4. Choisir le bon algorithme
Le planificateur de requêtes choisit l'algorithme automatiquement. Vous influencez sa décision indirectement en créant les bons index et en ajustant les paramètres de mémoire.
| Scénario | Algorithme probable |
|---|---|
| Petite table externe + table interne indexée | Nested Loop Join |
| Deux grandes tables, égalité, pas d'index utiles | Hash Join |
| Deux grandes tables, égalité, toutes deux triées / indexées en ordre | Merge Join |
Condition de non-égalité (<, >, BETWEEN) | Nested Loop Join (seule option) |
Conseils pratiques :
- Créez des index sur les colonnes de clés étrangères fréquemment utilisées dans les jointures — cela permet des Index Nested Loop et Merge Joins rapides.
- Si un Hash Join déverse sur le disque, envisagez d'augmenter
work_memou de restructurer la requête. - Utilisez
EXPLAIN ANALYZEpour inspecter l'algorithme réellement choisi par le planificateur et le temps pris par chaque étape :
EXPLAIN ANALYZE
SELECT a.first_name, a.last_name, f.title
FROM actor AS a
INNER JOIN film_actor AS fa ON a.actor_id = fa.actor_id
INNER JOIN film AS f ON fa.film_id = f.film_id;
Recherchez les mots-clés Hash Join, Merge Join ou Nested Loop dans le plan d'exécution pour identifier l'algorithme choisi et son coût.
Points clés de cette leçon
- Nested Loop Join itère les lignes dans des boucles imbriquées — rapide pour les petites tables avec des index de support, très lent pour les grandes tables non indexées ; le seul algorithme qui prend en charge les conditions de non-égalité.
- Hash Join construit une table de hachage en mémoire à partir de la plus petite table et la sonde — efficace pour les grandes tables non indexées jointes sur l'égalité, mais gourmand en mémoire.
- Merge Join lit simultanément deux flux pré-triés — idéal lorsque les données sont déjà ordonnées (ex. via un index) et que la jointure est sur l'égalité ; produit les résultats en ordre trié en bonus.
- Les trois algorithmes prennent en charge les jointures par égalité ; seul Nested Loop prend également en charge les conditions de plage.
- Vous influencez le choix du planificateur via les index, les paramètres mémoire (
work_mem) et la structure des requêtes — pas en spécifiant l'algorithme en SQL. - Utilisez toujours
EXPLAIN ANALYZEpour vérifier l'algorithme réellement utilisé et identifier où le temps est passé.